A few weeks ago, I was handed a spreadsheet that represented a massive cost-saving opportunity and a massive technical nightmare.
We had a massive 206M+ record workload sitting on Amazon DocumentDB Elastic. It was a powerhouse, but we were barely scratching the surface of its resources. It was like driving a Ferrari to the grocery store: expensive and unnecessary. Moving to the Standalone version was an obvious six-figure win, but there was a catch.
The standard way to move data in AWS is DMS (Database Migration Service). But DocumentDB Elastic doesn’t support native Change Data Capture (CDC). Without CDC, you can’t stream live updates. A naive snapshot and restore would have taken us offline for days.
In high-stakes engineering, you have to be both to be scrappy and pragmatic. My first thought wasn’t “let’s build a custom proxy.” It was “how can I do this with zero downtime without losing my mind?” But when the standard tools fail you, you don’t lower your goals; you change your architecture.
The Constraint: Protect the Product Engineers
We had three non-negotiables: absolute zero downtime, total data integrity, and zero application impact.
I’ve seen many migrations fail because they required just a few small changes to the application code. In a large organization, that is a trap. If you ask ten product teams to change their database logic for your cost-saving project, you’ve already lost. Their time is better spent building features for customers.
My goal was to make this migration invisible. I wanted the product teams to wake up one morning and find a smaller bill, without ever knowing we had swapped the engines while the car was doing 200mph on the highway.
Moving to the Network Layer
As I thought deeper about the problem, I realized that if I couldn’t get data out of the database (no CDC), I had to catch it before it got there.
My aha! moment was realizing I could apply an old-school technique: a TCP Proxy. If I could intercept the wire-protocol traffic between the service and the database, I would have total control.
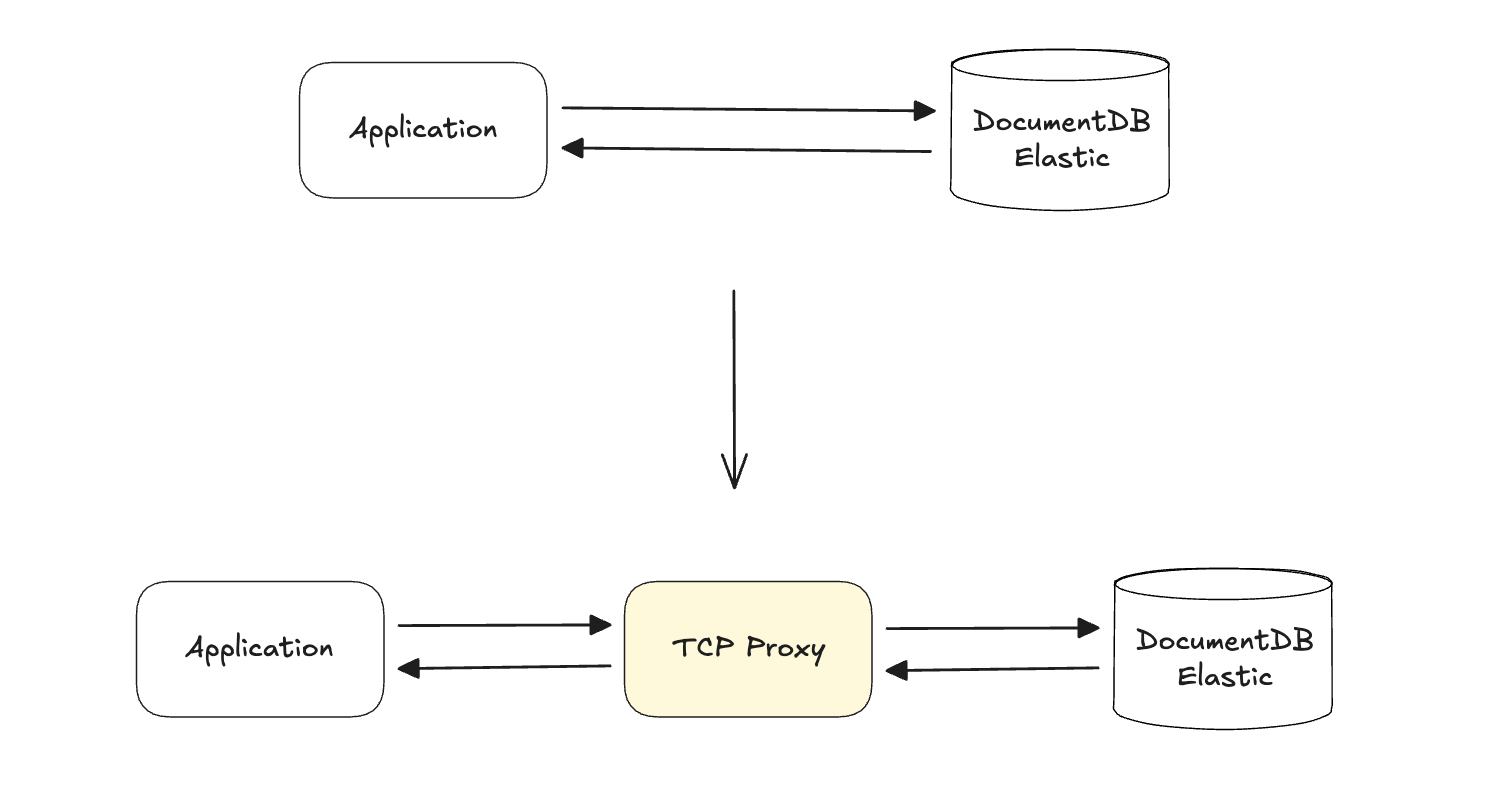
But building a MongoDB-compatible proxy in 30 days sounds like a suicide mission. Why did I think we could pull it off? Because I looked for the Golden Tickets, the specific simplifications that made the problem tractable:
- No Multi-Document Transactions: DocumentDB Elastic doesn’t support them. This meant I didn’t have to worry about complex distributed isolation levels.
- Single Service Scope: We only had to support a single Activity Ledger service. No need for a one-size-fits-all proxy.
- Idempotency: Every write in this service was idempotent. If I replayed an event log insert twice due to a network flicker, the result was the same.
With these realizations, the suicide mission turned into a solvable engineering problem.
Consistency vs. Latency
When you have a 30-day inception-to-production sprint, there is no room for a learning curve. I chose Go for the implementation because it is built for this kind of high-concurrency network plumbing and deep familiarity with the language. In a high-concurrency TCP environment, goroutines are a first-class citizen. We could handle 40 concurrent worker threads to replay traffic without breaking a sweat.
But we hit the classic distributed systems problem in PACELC theorem: Consistency vs. Latency. If the proxy waited for a write to succeed on both the old and new databases before responding, latency would double. That was unacceptable. Instead, I implemented a Write-Ahead Log (WAL).
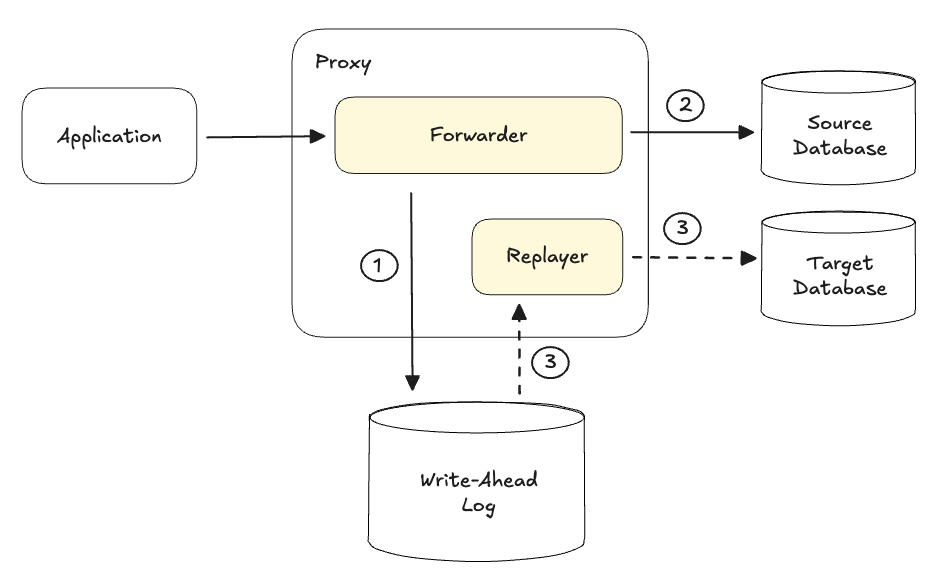
When a write hit the proxy:
- It was written to a local high-speed disk (the WAL).
- It was sent to the source database immediately.
- A background Replayer would then asynchronously suck the data out of the WAL and push it to the target database.
This decoupled the migration from the application’s critical path. The app stayed fast; the migration stayed invisible.
The Operational State Machine
When you are messing with the network layer of a production service, you don’t just flip a switch. You move through a series of deliberate, reversible states. I designed the proxy as a state machine to manage this risk because I realized that a naive replay would be a disaster.
If we started replaying the WAL immediately while the snapshot was still being restored, the target databasse would become a corrupted mess of out-of-order operations. The state machine ensured every mode was perfectly aligned with our step-by-step strategy.
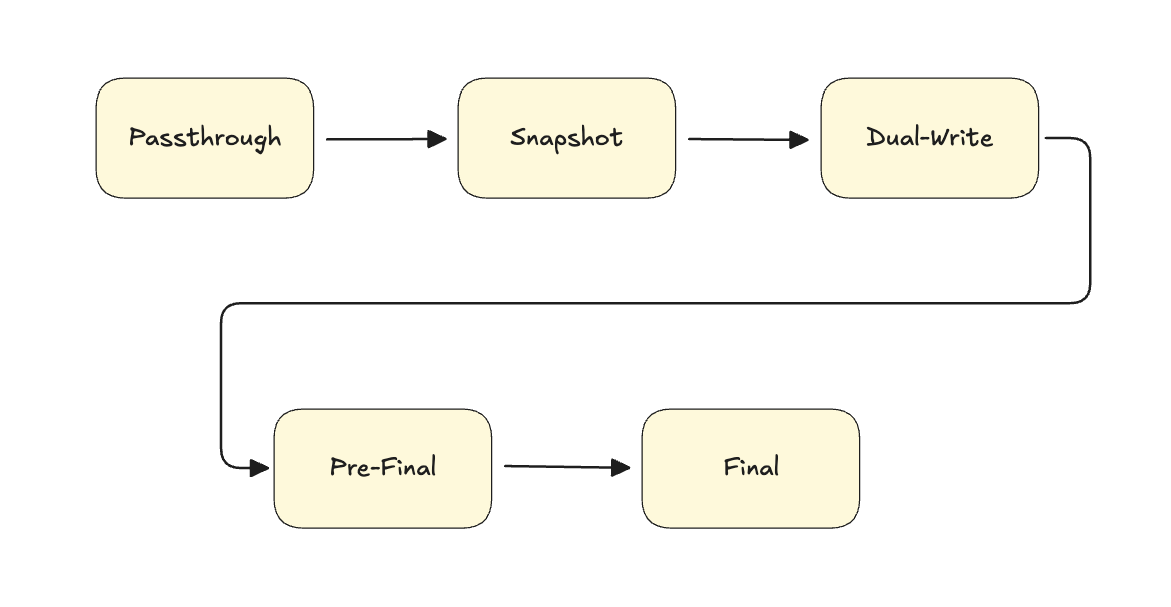
We started in Passthrough mode: a transparent pipe to verify the proxy was stable. Then we moved to Snapshot mode, where the proxy began recording writes to the WAL while we took our data baseline. Once the restore was finished, we engaged Dual-Write mode: the background Replayer started draining the WAL to sync the two clusters.
| State | Reads | Writes to Source | Writes to Target | WAL Status |
|---|---|---|---|---|
| Passthrough | Source | Yes | No | Off |
| Snapshot | Source | Yes | No | Recording |
| Dual-Write | Source | Yes | Yes (via Replayer) | Draining |
| Pre-Final | Source | Yes | Yes (via Replayer) | Minimum-to-zero lag |
| Final | Target | No | Yes (Direct) | Drained |
Then came the Pre-Final mode. This was a safety interlock. It acted as a warning: “hey, we are about to cross the point of no return.” Finally, we reached the Final mode. This is where we buffered incoming writes for a few milliseconds to let the Replayer catch the very last tail of the log. Once they were in sync, we route all traffic to the new Standalone cluster.
This stepwise approach turned a high-stakes migration into a series of boring, predictable events.
The Compromises We Lived With
Engineering is the art of making tradeoffs. To deliver this in 30 days, we had to make some choices that would make a purist uncomfortable.
First, Standalone Simplicity vs. Distributed Complexity. We deployed the proxy on a single, high-performance EC2 instance rather than a multi-node cluster. A cluster would have given us High Availability, but it would have introduced the Consensus Problem. Keeping sequence numbers and WAL entries in sync across multiple nodes requires Raft or Paxos. That would have added months of development time and introduced network jitter. We accepted the risk of a single point of failure for the duration of the migration window in exchange for sub-millisecond performance.
Second, EC2 vs. Kubernetes. We are a K8s-first shop, but for this, we went with raw EC2. We needed ultra-low network jitter and high-speed disk I/O for the WAL. Bypassing the container runtime gave us direct, uncontested access to the hardware. It was a tradeoff: we gave up the convenience of container orchestration for deterministic performance.
Third, One-Way vs. Two-Way Doors. We initially explored building a fully automated ROLLBACK mode to keep our options open. But with 200M+ records, the complexity of managing a reverse-sync in a one-month window introduced massive new risks. We made a deliberate choice: we traded the theoretical safety of an automated rollback for the practical certainty of mathematical validation. We decided that if we could prove the data was identical, we didn’t need a way back.
The Moving Target Problem
How do you prove that 200 million records are identical when the data is constantly changing?
If you compare the source and target at 10:00 AM, the target will always be slightly behind because of replication lag. A naive diff would show thousands of errors. I call this the Moving Target Problem.
To solve this, we built the Adjudicator. It used a two-phase check:
- Phase 1 (Discovery): Scan and find Suspect records that missing or don’t match.
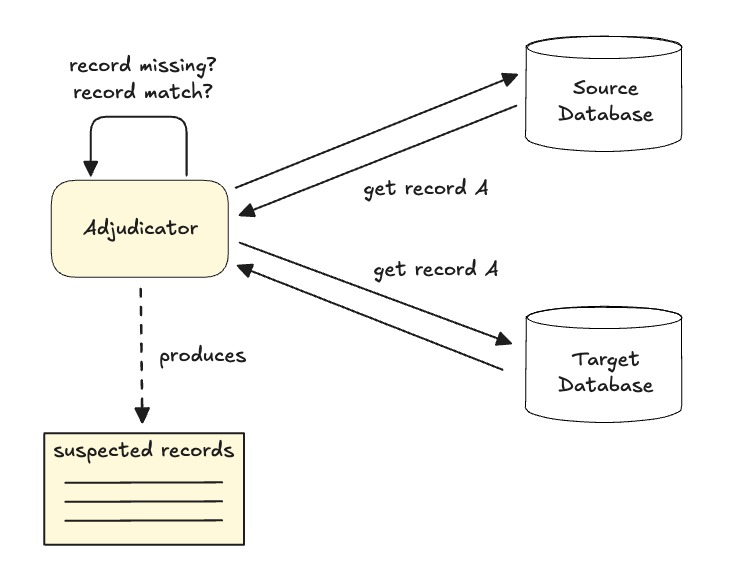
- Phase 2 (Verification): Wait a few seconds, then re-check only those suspects.
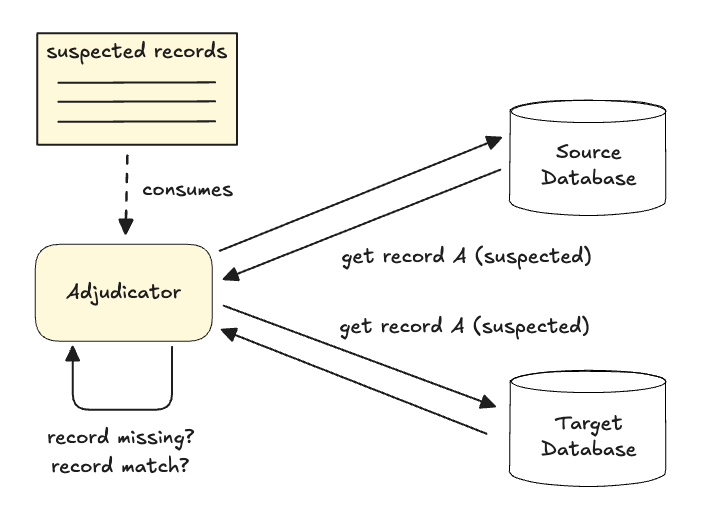
This delay gave the Replayer time to catch up. If the mismatch persisted after the second check, only then did we consider it a real error and repair the record using separate tool. This allowed us to mathematically prove consistency on a live system without stopping traffic.
The Cutover: Sub-second Silence
For the final flip, we didn’t use DNS. DNS TTLs are a lie: even if you set them to seconds, clients and middleware cache IP addresses unpredictably. In a high-velocity migration, even a five-second overlap creates a split-brain nightmare where data is written to two different places simultaneously.
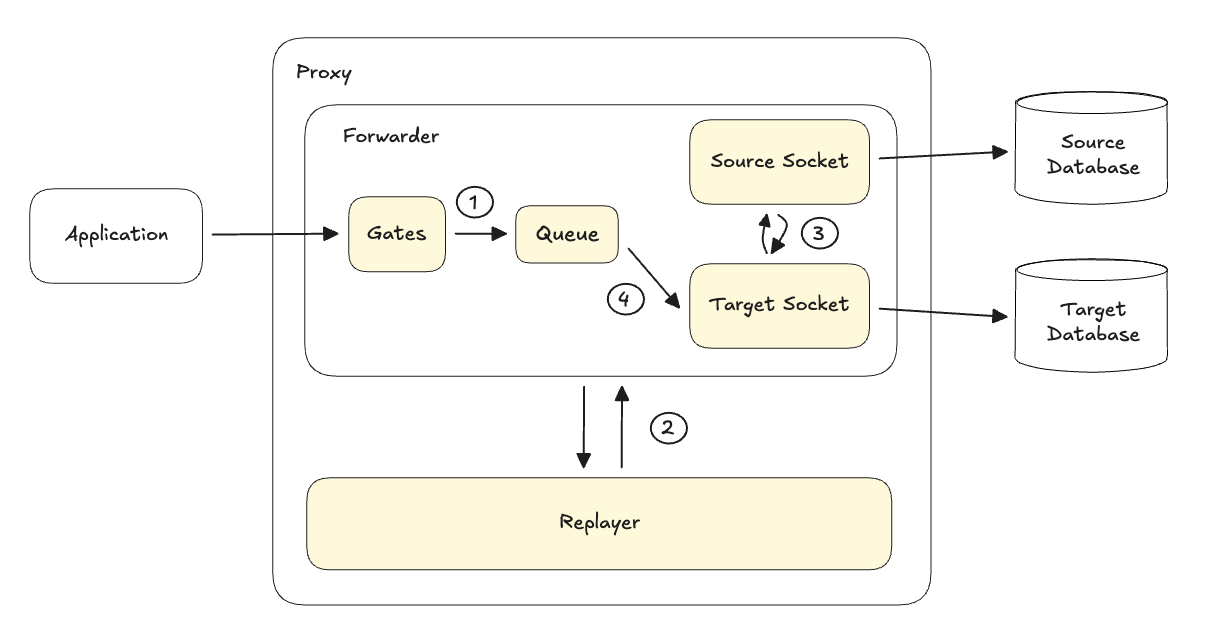
Instead, we moved the proxy into Final mode. Inspired by VTGate in the Vitess project, we used a Buffer and Flip logic which triggered a tightly orchestrated, atomic sequence:
- The proxy paused incoming queries through the Gates for a fraction of a second and buffering them in the Queue.
- It waited for the Replayer to finish the last of the WAL to ensure zero lag.
- It swapped its internal pointers from the Source Socket to the Target Socket.
- It opened the Gates, and the Target Socket flushed all buffered queries from the Queue into the Target database.
From the service’s perspective, there was a tiny hiccup in latency. No dropped connections. No service errors. Just a clean break.
Conclusion
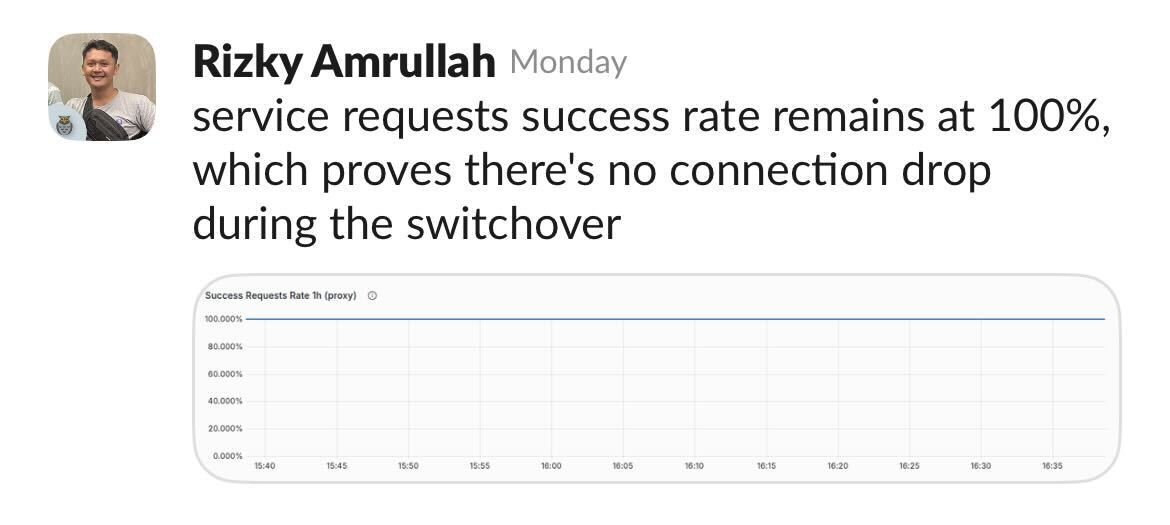
We moved 200M+ records with zero downtime. But more importantly, we did it without distracting our product teams.
Engineering is all about making the right tradeoffs given the constraints you have. This isn’t just true for distributed systems; it’s true for every system architecture. We traded the complexity of a custom proxy for the simplicity of a non-disruptive migration.
Sometimes, the expensive engineering effort of building a custom tool is actually the cheapest path for the company. The highest compliment for an SRE is that you did something massive, and nobody outside your team even noticed. 🥂